ExecuteScript is a glorified onTrigger() call where you can work with incoming flow files, create new ones, add attributes, etc. It is meant for the "per-flowfile" paradigm, where the other aspects of the Processor API do not apply. But perhaps you want a full-fledged Processor local to your cluster and want to avoid the overhead of building a NAR, submitting the code, etc. etc. With InvokeScriptedProcessor, you can use Javascript, Groovy, Jython, Lua, or JRuby to create a Processor implementation. InvokeScriptedProcessor will delegate methods such as getPropertyDescriptors, getRelationships, onTrigger, etc. to the scripted processor. This has more power than ExecuteScript because custom properties and relationships can be defined, plus more methods than onTrigger() can be implemented.
One main difference between ExecuteScript and InvokeScriptedProcessor is that REL_SUCCESS and REL_FAILURE are the only two relationships available to ExecuteScript and are passed in automatically. For InvokeScriptedProcessor, all relationships (and all other Processor interface methods) must be defined by the scripted processor, and a variable named "processor" must be defined and point to a valid instance of the scripted processor.
Below is an example of a bare-bones scripted Processor that expects input from a CSV-formatted flow file (coming from the random user generation site https://randomuser.me/, the query is http://api.randomuser.me/0.6/?format=csv&nat=us&results=100. It splits on commas and takes the third and fourth (indexes 2 and 3) values (first and last name, respectively), then outputs the capitalized first name followed by the capitalized last name:
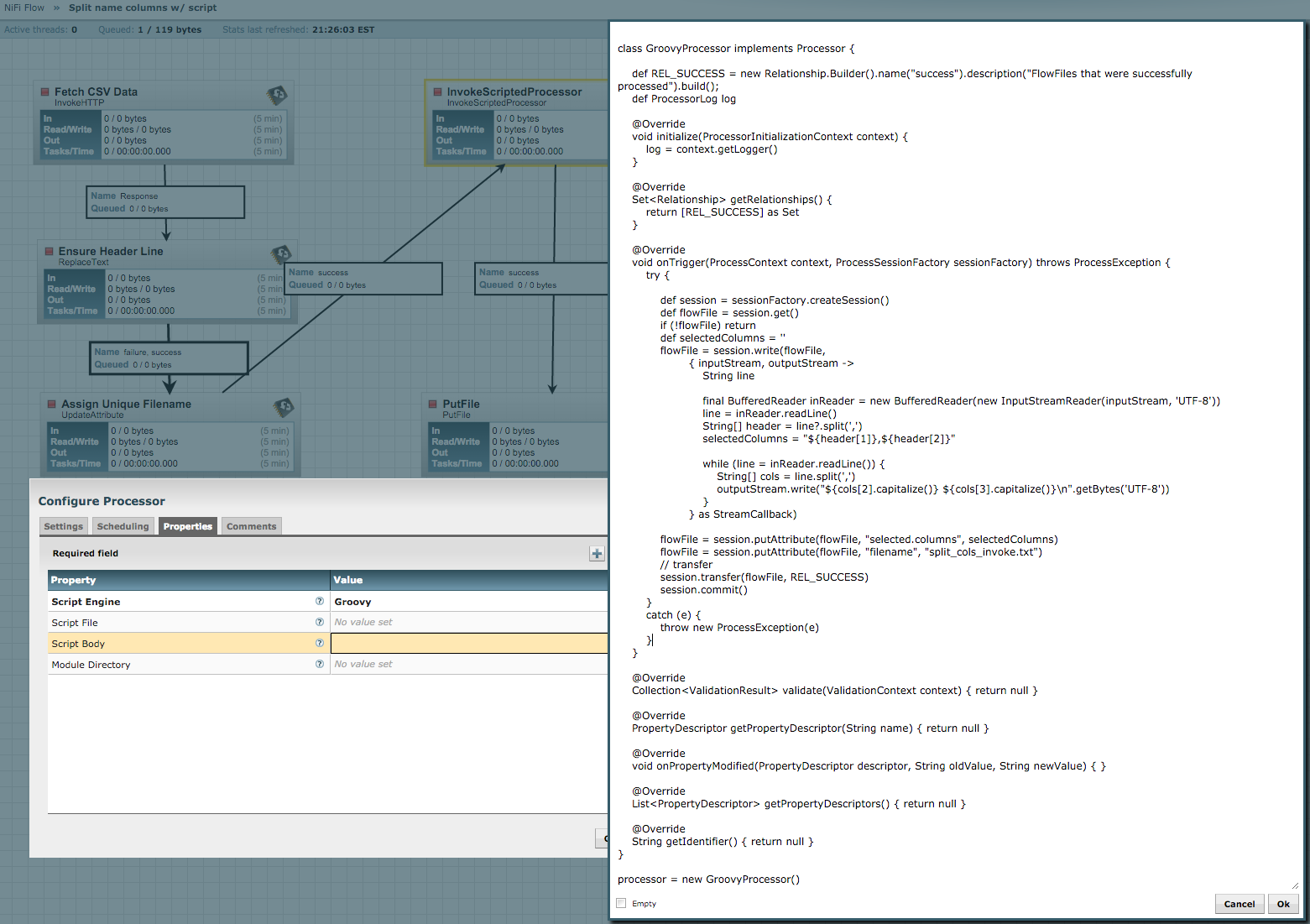
class GroovyProcessor implements Processor {
def REL_SUCCESS = new Relationship.Builder().name("success").description("FlowFiles that were successfully processed").build();
def ProcessorLog log
@Override
void initialize(ProcessorInitializationContext context) {
log = context.getLogger()
}
@Override
Set<Relationship> getRelationships() {
return [REL_SUCCESS] as Set
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throws ProcessException {
try {
def session = sessionFactory.createSession()
def flowFile = session.get()
if (!flowFile) return
def selectedColumns = ''
flowFile = session.write(flowFile,
{ inputStream, outputStream ->
String line
final BufferedReader inReader = new BufferedReader(new InputStreamReader(inputStream, 'UTF-8'))
line = inReader.readLine()
String[] header = line?.split(',')
selectedColumns = "${header[1]},${header[2]}"
while (line = inReader.readLine()) {
String[] cols = line.split(',')
outputStream.write("${cols[2].capitalize()} ${cols[3].capitalize()}\n".getBytes('UTF-8'))
}
} as StreamCallback)
flowFile = session.putAttribute(flowFile, "selected.columns", selectedColumns)
flowFile = session.putAttribute(flowFile, "filename", "split_cols_invoke.txt")
// transfer
session.transfer(flowFile, REL_SUCCESS)
session.commit()
}
catch (e) {
throw new ProcessException(e)
}
}
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String newValue) { }
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
processor = new GroovyProcessor()
Besides the relationship differences, there are a couple of other noteworthy differences between ExecuteScript and InvokeScriptedProcessor (plus the latter's need to implement Processor API methods):
1) ExecuteScript handles the session.commit() for you, but InvokeScriptedProcessor does not.
2) ExecuteScript has a "session" variable, where the InvokeScriptedProcessor's onTrigger() method must call sessionFactory.createSession()
A future post will cover the other Processor API methods, specifically those that add properties and/or relationships. This is meant as an introduction to writing a Processor in a scripting language using InvokeScriptedProcessor.
The template for the above processor (and the associated incoming data) is available as a Gist (here). As always I welcome all comments, questions, and suggestions.
Cheers!
Hi,
ReplyDeleteThank you very much for the tutorial. I am new to Nifi and trying out some use cases. I wrote a Jython script where I read from an xml file(rss) and then convert it into a string and write to outputStream and routed to putFile. The problem I am facing is that the data is getting queued in the connection to ExecuteScript and not getting into the processor. I am posting the code I wrote here in the ExecuteScript Script body. Did I need to point it to a module directory?
import xml.etree.ElementTree as ET
import java.io
from org.apache.commons.io import IOUtils
from java.nio.charset import StandardCharsets
from org.apache.nifi.processor.io import StreamCallback
class xmlParser(StreamCallback):
def __init__(self):
pass
def process(self,inputStream,outputStream):
text= IOUtils.ToString(inputStream,StandardCharsets.UTF_8)
xmlRoot = ET.fromstring(text);
extracted_list=[]
for elmnts in xmlRoot.fromall('item'):
title= elmnts.find("title").text
description = elmnts.find("description").text
extracted_list.append(title)
extracted_list.append(description)
str_extract = ''.join(extracted_list)
outputStream.write(bytearray(str_extract.encode('utf-8')))
flowFile = session.get()
if(flowFile!=None):
flowFile = session.write(flowFile,xmlParser())
flowFile = session.putAtrribute(flowFile, 'filename', 'rss_feed.xml')
session.transfer(flowFile, REL_SUCCESS)
session.commit()
If you can help me with this, it would be great.
I can't see the indentation in this script so it's hard to tell what's going on. Also this post is for InvokeScriptedProcessor but it sounds like you are using ExecuteScript. There is an example of a Jython script here: http://funnifi.blogspot.com/2016/03/executescript-json-to-json-revisited_14.html.
ReplyDeleteIf you are using ExecuteScript, then you don't need the session.commit(), ExecuteScript will do that for you. If you are using InvokeScriptedProcessor, then you have to create a session from the sessionFactory and commit it at the end (see above post). With ExecuteScript you can just do session.get() and session.transfer() and all transactions will be committed automatically at the end.
Please let me know if you continue to have trouble, you can also ask the question on the user and/or dev mailing list for NiFi: https://nifi.apache.org/mailing_lists.html
Cheers!
@Matt Burgess : Is that possible to execute wordcount program (pyspark) in executescript processor? and if it is how can we configure it ?
ReplyDeleteMatt,
ReplyDeleteCan you please verify around line 5 of your script, where it says:
def ProcessorLog log
In my opinion it should be either
def log
or
ComponentLog log
That, at least, works for me.
Yes either of your suggestions will work for NiFi 1.x+ I should have used "def log" from the outset, but wanted to illustrate the type in case people wanted to know what class it was. This script was written against a version of NiFi that had ProcessorLog. NiFi has since updated its API to pass in a ComponentLog and the ProcessorLog was removed.
DeleteThis comment has been removed by the author.
ReplyDeleteTeradata is basically a database. The purpose of teradatabase is for creating a table, column, row, domain, primary key etc. you can get further more information. Teradata dba Online Training
ReplyDelete