We could use dynamic properties (explained in the Developer's Guide and in an earlier post), as they are passed into ExecuteScript as variables. However the user of the processor would have to know which properties to add and fill in, and there's no good way to get that information to the user (at least with ExecuteScript).
However, InvokeScriptedProcessor lets you provide a scripted implementation of a full Processor instance. This means you can define your own properties and relationships, along with documentation and validation of them. Your script could provide capabilities that depend on the way the user of the processor configures the processor, without having to interact with the script at all!
I'll illustrate this below, but I think the coolest point is: A template with a single InvokeScriptedProcessor (that contains a working script) can be dragged onto the canvas and basically acts like dragging your custom processor onto the canvas! When the user opens the dialog, they will see the properties/relationships you added, and they will be validated just like the normal ones (script language, body, etc.) that come with the processor.
The scripted processor needs only implement the Processor interface, which in turn extends AbstractConfigurableComponent. A basic Groovy skeleton with a class including a set of overridden interface methods looks like this:
class MyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { }
@Override
Set<Relationship> getRelationships() { return [] as Set }
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throws ProcessException {
// do stuff
}
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) {
return null
}
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String newValue) { }
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return [] as List }
@Override
String getIdentifier() { return 'MyProcessor-InvokeScriptedProcessor' }
}
processor = new MyProcessor()
Note that the class must implement Processor and declare a variable named "processor" that contains an instance of the class. This is the convention required by the InvokeScriptedProcessor.
IMPORTANT: Although you may find in NiFi code that many processors extend either AbstractProcessor or AbstractSessionFactoryProcessor, your script will most likely NOT work if it extends one of these classes. This is due to the validate() method of these classes being declared final, and the basic implementation will expect the set of Supported Property Descriptors to include the ones that come with the InvokeScriptedProcessor (like Script File), but will only use the list that your scripted processor provides. There might be a hack to get around this but even if possible, it's not likely worth it.
Moving on, let's say we want to create a reusable scripted processor that works like GenerateFlowFile but allows the user to provide the content of the flow file as well as the value of its "filename" attribute. Moreover, maybe the content could include NiFi Expression Language (EL) constructs like ${hostname()}. Since the content may have something like EL statements but the user might not want them evaluated as such, we should let the user decide whether to evaluate the content for EL statements before writing to the flow file. Lastly, this is a "generate" processor so we only need a "success" relationship; "failure" doesn't really make sense here. Having said that, it will be important to catch all Exceptions that your code can throw; wrap each in a ProcessException and re-throw, so the framework can handle it correctly.
So the list of things to do:
- Add a "success" relationship and return it in (in a Set) from getRelationships()
- Add a "File Content" property to contain the intended content of the flow file (may include EL)
- Add a "Evaluate Expressions in Content" property for the user to indicate whether to evaluate the content for EL
- Add an optionally-set "Filename" property to override the default "filename" attribute.
- When the processor is triggered, create a flow file, write the content (after possibly evaluating EL), and possibly set the filename attribute
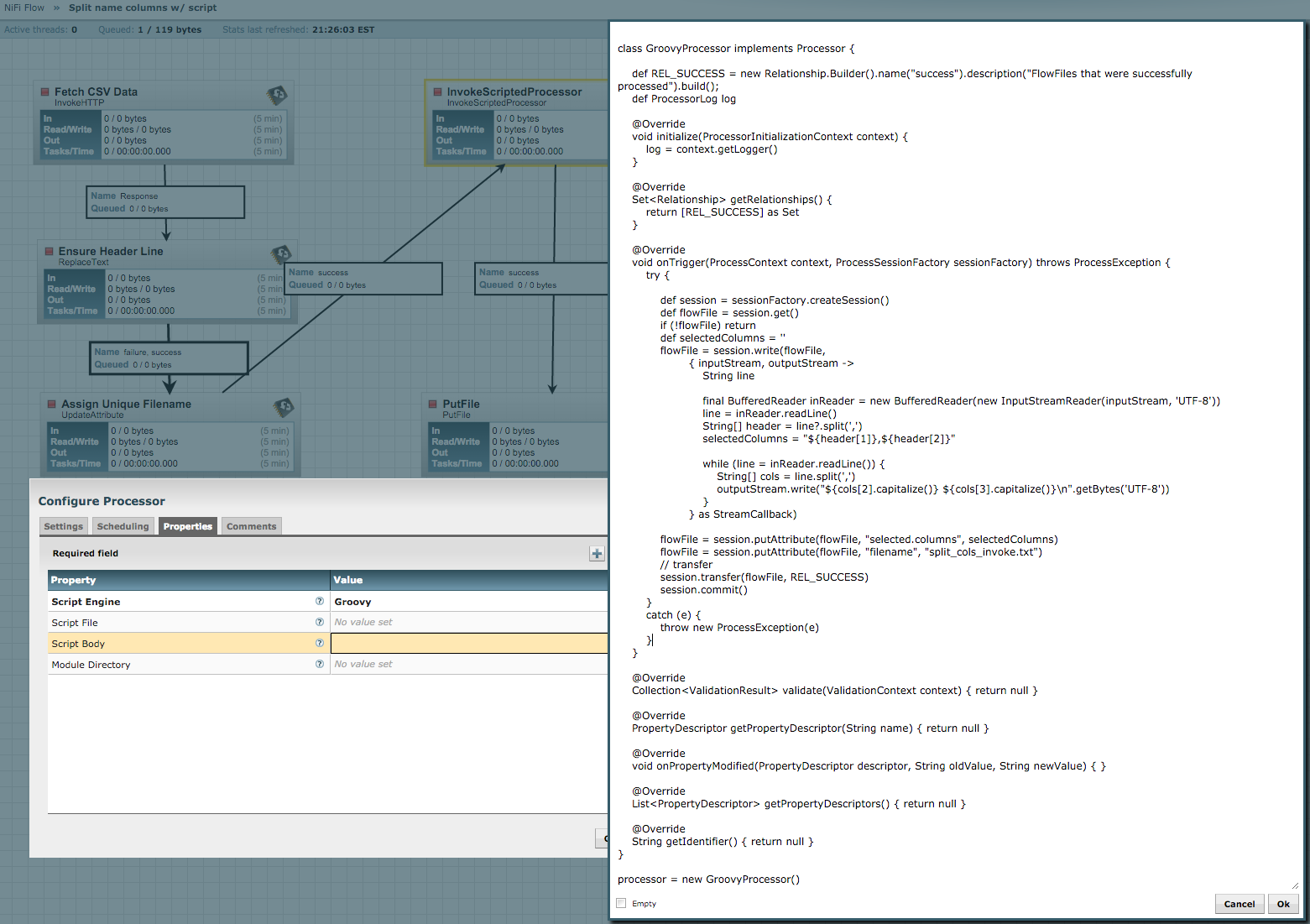
Here is some example Groovy code to do just that:
class GenerateFlowFileWithContent implements Processor {
def REL_SUCCESS = new Relationship.Builder()
.name('success')
.description('The flow file with the specified content and/or filename was successfully transferred')
.build();
def CONTENT = new PropertyDescriptor.Builder()
.name('File Content').description('The content for the generated flow file')
.required(false).expressionLanguageSupported(true).addValidator(Validator.VALID).build()
def CONTENT_HAS_EL = new PropertyDescriptor.Builder()
.name('Evaluate Expressions in Content').description('Whether to evaluate NiFi Expression Language constructs within the content')
.required(true).allowableValues('true','false').defaultValue('false').build()
def FILENAME = new PropertyDescriptor.Builder()
.name('Filename').description('The name of the flow file to be stored in the filename attribute')
.required(false).expressionLanguageSupported(true).addValidator(StandardValidators.NON_EMPTY_VALIDATOR).build()
@Override
void initialize(ProcessorInitializationContext context) { }
@Override
Set<Relationship> getRelationships() { return [REL_SUCCESS] as Set }
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throws ProcessException {
try {
def session = sessionFactory.createSession()
def flowFile = session.create()
def hasEL = context.getProperty(CONTENT_HAS_EL).asBoolean()
def contentProp = context.getProperty(CONTENT)
def content = (hasEL ? contentProp.evaluateAttributeExpressions().value : contentProp.value) ?: ''
def filename = context.getProperty(FILENAME)?.evaluateAttributeExpressions()?.getValue()
flowFile = session.write(flowFile, { outStream ->
outStream.write(content.getBytes("UTF-8"))
} as OutputStreamCallback)
if(filename != null) { flowFile = session.putAttribute(flowFile, 'filename', filename) }
// transfer
session.transfer(flowFile, REL_SUCCESS)
session.commit()
} catch(e) {
throw new ProcessException(e)
}
}
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) {
switch(name) {
case 'File Content': return CONTENT
case 'Evaluate Expressions in Content': return CONTENT_HAS_EL
case 'Filename': return FILENAME
default: return null
}
}
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String newValue) { }
@Override
List<PropertyDescriptor>> getPropertyDescriptors() { return [CONTENT, CONTENT_HAS_EL, FILENAME] as List }
@Override
String getIdentifier() { return 'GenerateFlowFile-InvokeScriptedProcessor' }
}
processor = new GenerateFlowFileWithContent()
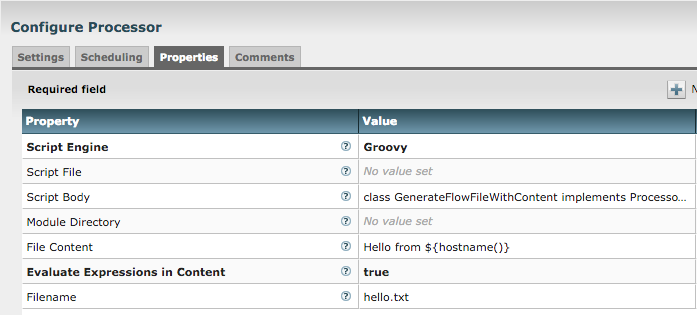
When this is entered into the Script Body of an InvokeScriptedProcessor, with the language set to Groovy and then applied (by clicking Apply on the dialog), then when the dialog is reopened you should see the relationships set to only "success" and the properties added to the config dialog:

At this point you can save the single processor as a template, calling it perhaps GenerateFlowFileWithContent or something. Now it is a template that is basically reusable as a processor. Try dragging it onto the canvas and entering some values, then wiring it to some other processor like PutFile (to see if it works):
Once the success relationship has been satisfied, that instance should be good to go:

Hopefully this has illustrated the power and flexibility of InvokeScriptedProcessor, and how it can be used to create reusable processor templates with custom logic, without having to construct and deploy a NAR. The example template is available as a Gist (here); as always I welcome all comments, questions, and suggestions.
Cheers!