ExecuteScript is a glorified onTrigger() call where you can work with incoming flow files, create new ones, add attributes, etc. It is meant for the "per-flowfile" paradigm, where the other aspects of the Processor API do not apply. But perhaps you want a full-fledged Processor local to your cluster and want to avoid the overhead of building a NAR, submitting the code, etc. etc. With InvokeScriptedProcessor, you can use Javascript, Groovy, Jython, Lua, or JRuby to create a Processor implementation. InvokeScriptedProcessor will delegate methods such as getPropertyDescriptors, getRelationships, onTrigger, etc. to the scripted processor. This has more power than ExecuteScript because custom properties and relationships can be defined, plus more methods than onTrigger() can be implemented.
One main difference between ExecuteScript and InvokeScriptedProcessor is that REL_SUCCESS and REL_FAILURE are the only two relationships available to ExecuteScript and are passed in automatically. For InvokeScriptedProcessor, all relationships (and all other Processor interface methods) must be defined by the scripted processor, and a variable named "processor" must be defined and point to a valid instance of the scripted processor.
Below is an example of a bare-bones scripted Processor that expects input from a CSV-formatted flow file (coming from the random user generation site https://randomuser.me/, the query is http://api.randomuser.me/0.6/?format=csv&nat=us&results=100. It splits on commas and takes the third and fourth (indexes 2 and 3) values (first and last name, respectively), then outputs the capitalized first name followed by the capitalized last name:
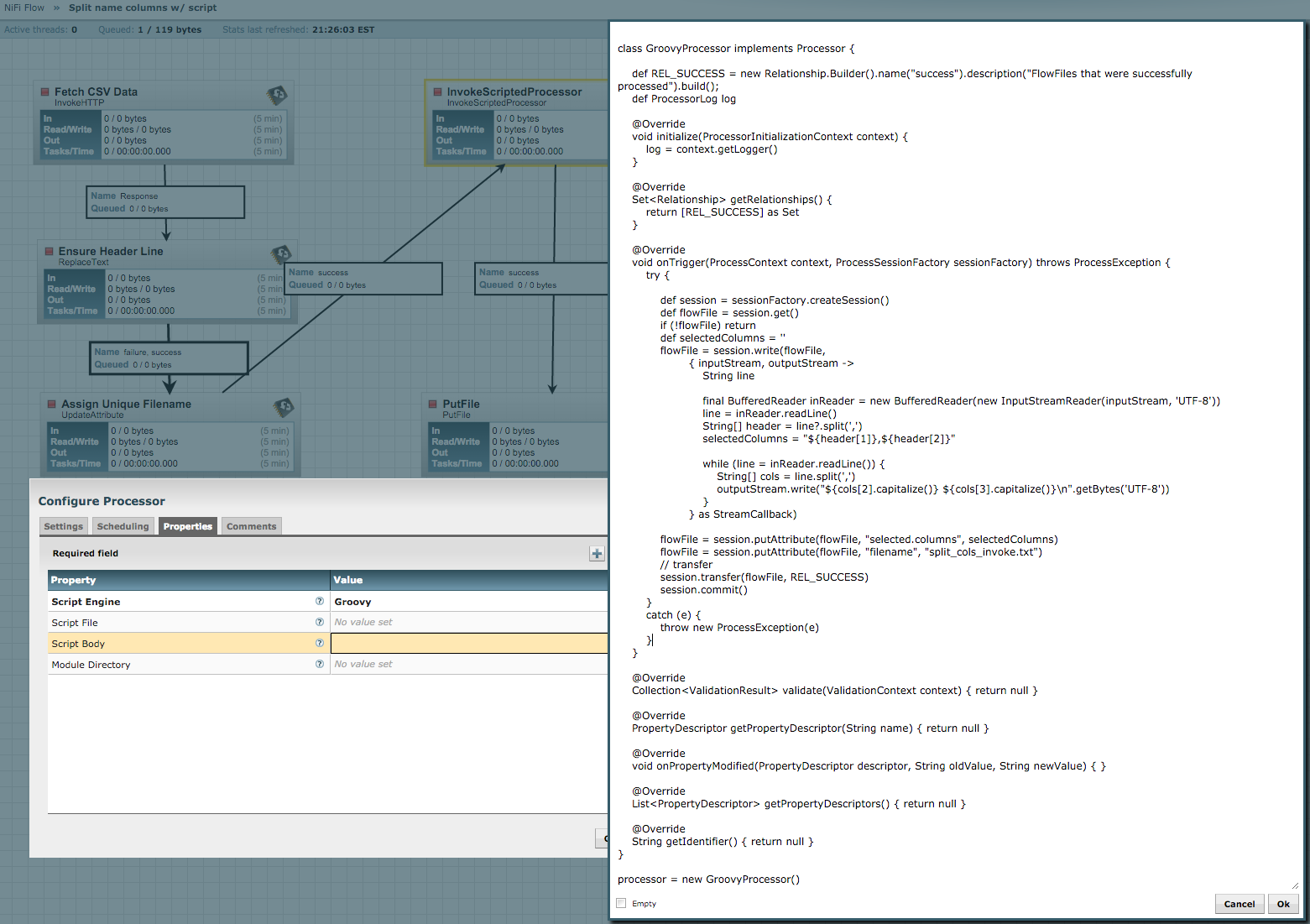
class GroovyProcessor implements Processor {
def REL_SUCCESS = new Relationship.Builder().name("success").description("FlowFiles that were successfully processed").build();
def ProcessorLog log
@Override
void initialize(ProcessorInitializationContext context) {
log = context.getLogger()
}
@Override
Set<Relationship> getRelationships() {
return [REL_SUCCESS] as Set
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throws ProcessException {
try {
def session = sessionFactory.createSession()
def flowFile = session.get()
if (!flowFile) return
def selectedColumns = ''
flowFile = session.write(flowFile,
{ inputStream, outputStream ->
String line
final BufferedReader inReader = new BufferedReader(new InputStreamReader(inputStream, 'UTF-8'))
line = inReader.readLine()
String[] header = line?.split(',')
selectedColumns = "${header[1]},${header[2]}"
while (line = inReader.readLine()) {
String[] cols = line.split(',')
outputStream.write("${cols[2].capitalize()} ${cols[3].capitalize()}\n".getBytes('UTF-8'))
}
} as StreamCallback)
flowFile = session.putAttribute(flowFile, "selected.columns", selectedColumns)
flowFile = session.putAttribute(flowFile, "filename", "split_cols_invoke.txt")
// transfer
session.transfer(flowFile, REL_SUCCESS)
session.commit()
}
catch (e) {
throw new ProcessException(e)
}
}
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String newValue) { }
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
processor = new GroovyProcessor()
Besides the relationship differences, there are a couple of other noteworthy differences between ExecuteScript and InvokeScriptedProcessor (plus the latter's need to implement Processor API methods):
1) ExecuteScript handles the session.commit() for you, but InvokeScriptedProcessor does not.
2) ExecuteScript has a "session" variable, where the InvokeScriptedProcessor's onTrigger() method must call sessionFactory.createSession()
A future post will cover the other Processor API methods, specifically those that add properties and/or relationships. This is meant as an introduction to writing a Processor in a scripting language using InvokeScriptedProcessor.
The template for the above processor (and the associated incoming data) is available as a Gist (here). As always I welcome all comments, questions, and suggestions.
Cheers!