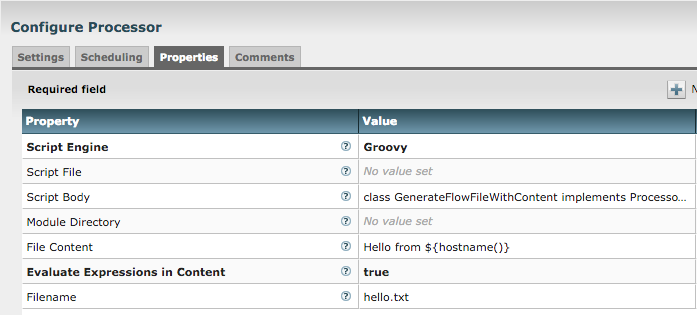
As a different approach, you can use ExecuteScript or InvokeScriptedProcessor, along with a third-party library for executing remote commands with SSH. For this post, I will be using Groovy as the scripting language and Sshoogr, which is a very handy SSH DSL for Groovy.
Sshoogr can be installed via SDK Manager or downloaded (from Maven Central for example). The key is to have all the libraries (Sshoogr itself and its dependencies) in a directory somewhere. Then you point to the directory in ExecuteScript's Module Directory property, and those JARs will be available to the Groovy script.
In order to make this example fairly flexible, I chose a few conventions. First, the commands to be executed are expected to be on individual lines of an incoming flow file. Next, the configuration parameters (such as hostname, username, password, and port) are added to ExecuteScript as dynamic properties. Note that the password property is not sensitive in this case; if you want that, use InvokeScriptedProcessor and explicitly add the properties (specifying password as sensitive).
For Sshoogr to work (at least for this example), it is expected that the RSA key for the remote node is in the NiFi user's ~/.ssh/known_hosts file. Because of OS and other differences, sometimes the SSH connection will fail due to strict host key checking, so in the script we will disable that in Sshoogr.
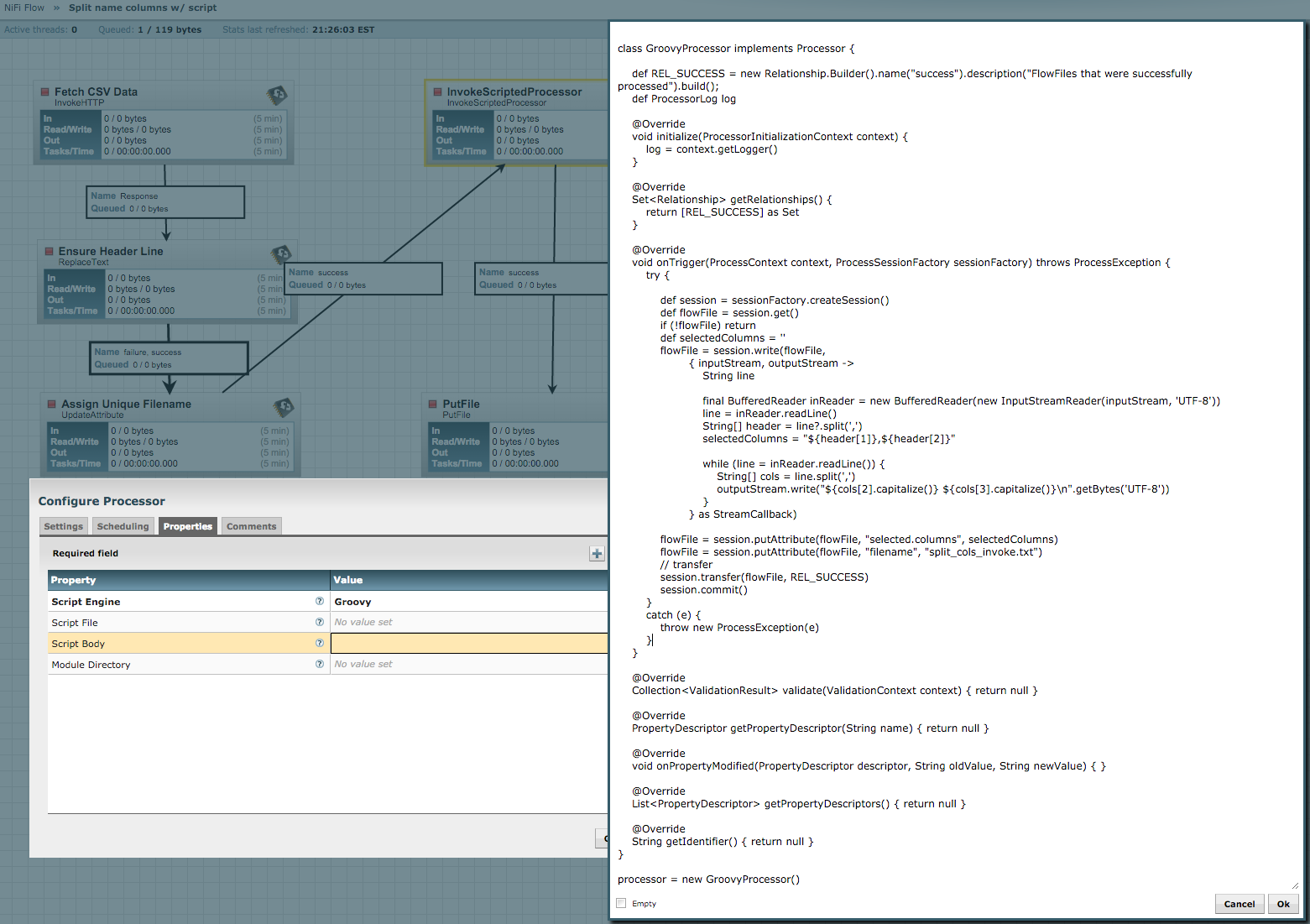
Now to the script. We start with the standard code for requiring an input flow file, and then use session.read() to get each line into a list called commands:
def flowFile = session.get()
if(!flowFile) return
def commands = []
// Read in one command per line
session.read(flowFile, {inputStream ->
inputStream.eachLine { line -> commands << line }
} as InputStreamCallback)
Then we disable strict host key checking:options.trustUnknownHosts = trueThen we use the Sshoogr DSL to execute the commands from the flow file:
def result = null
remoteSession {
host = sshHostname.value
username = sshUsername.value
password = sshPassword.value
port = Integer.parseInt(sshPort.value)
result = exec(showOutput: true, failOnError: false, command: commands.join('\n'))
}
Here we are using the aforementioned ExecuteScript dynamic properties (sshHostname, sshUsername, sshPassword, sshPort). Later in the post, a screenshot below shows them after having been added to the ExecuteScript configuration.The exec() method is the powerhouse of Sshoogr. In this case we want the output of the commands (to put in an outgoing flowfile). Also I've set "failOnError" to false just so all commands will be attempted, but it is likely that you will want this to be true such that if a command fails, none of the following commands will be attempted. The final parameter in this example is "command". If you don't use the "named-parameter" (aka Map) version of exec() and just want to execute the list of commands (without setting "showOutput" for example), then exec() will take a Collection:
exec(commands)In our case though, the exec() method will turn the "command" parameter into a string, so instead of just passing in the List "commands", we need to turn it back into a line-by-line string, so we use join('\n').
The next part of the script is to overwrite the incoming flow file, or if we could've created a new one with the original as a parent. If using ExecuteScript and creating a new flow file, be sure to remove the original. If using InvokeScriptedProcessor, you could define an "original" relationship and route the incoming flow file to that.
flowFile = session.write(flowFile, { outputStream ->
result?.output?.eachLine { line ->
outputStream.write(line.bytes)
outputStream.write('\n'.bytes)
}
} as OutputStreamCallback)
Finally, using result.exitStatus, we determine whether to route the flow file to success or failure:session.transfer(flowFile, result?.exitStatus ? REL_FAILURE : REL_SUCCESS)The full script for this example is as follows:
import static com.aestasit.infrastructure.ssh.DefaultSsh.*
def flowFile = session.get()
if(!flowFile) return
def commands = []
// Read in one command per line
session.read(flowFile, {inputStream ->
inputStream.eachLine { line -> commands << line }
} as InputStreamCallback)
options.trustUnknownHosts = true
def result = null
remoteSession {
host = sshHostname.value
username = sshUsername.value
password = sshPassword.value
port = Integer.parseInt(sshPort.value)
result = exec(showOutput: true, failOnError: false, command: commands.join('\n'))
}
flowFile = session.write(flowFile, { outputStream ->
result?.output?.eachLine { line ->
outputStream.write(line.bytes)
outputStream.write('\n'.bytes)
}
} as OutputStreamCallback)
session.transfer(flowFile, result?.exitStatus ? REL_FAILURE : REL_SUCCESS)
Moving now to the ExecuteScript configuration:
Here I am connecting to my Hortonworks Data Platform (HDP) Sandbox to run Hadoop commands and such, the default settings are shown and you can see I've pasted the script into Script Body, and my Module Directory is pointing at my Sshoogr download folder. I added this to a simple flow that generates a flow file, fills it with commands, runs them remotely, then logs the output returned from the session:

For this example I ran the following two commands:
hadoop fs -ls /user echo "Hello World!" > here_i_am.txtIn the log (after LogAttribute runs with payload included), I see the following:

And on the sandbox I see the file has been created with the expected content:

As you can see, this post described how to use ExecuteScript with Groovy and Sshoogr to execute remote commands coming from flow files. I created a Gist of the template, but it was created with an beta version of Apache NiFi 1.0 so it may not load into earlier versions (0.x). However all the ingredients are in this post so it should be easy to create your own flow, please let me know how/if it works for you :)
Cheers!