In NiFi version 1.19.0, the UpdateDatabaseTable processor was added to help with database schema migration and to make replication of database tables easier. This processor checks the schema of the incoming records against the target database. As in the following example, if the target table does not exist, the processor can either fail the FlowFile or create the table for you:

Having the processor create the table (if it doesn't already exist) allows you to take data from any source/flow and land it in a database even if that table is not already there. This removes the previous need to set up the target tables with the intended schema manually and beforehand. I will illustrate this with a simple flow:

The flow uses GenerateFlowFile to issue some simple sample data, but in practice it will be common to use QueryDatabaseTableRecord to incrementally fetch rows from a source database table. The flow then sends the FlowFiles to UpdateDatabaseTable, but any number of transformations of the data are possible in NiFi before the records are ready for the desired target table. This is the configuration of UpdateDatabaseTable for this example:

It should be noted here (and will be noted later) that the outgoing FlowFiles from the UpdateDatabaseTable processor will have a 'output.table' attribute set to the target table name. This can (and will in this example) be used later to refer to the table that was created/updated.
When the flow is started, the target table 'udt_test' does not yet exist in the database:

Taking a look at an example FlowFile, you can see the schema of the data (i.e. the JSON structure) and thus the intended target table definition:

After starting this flow and seeing at least one FlowFile progress through UpdateDatabaseTable successfully, we can now verify the desired target table does indeed exist in the target database:

And after running with the following configuration of PutDatabaseRecord:

We can see that not only has the table been created (using the aforementioned 'output.table' attribute), but the record has been inserted successfully:

The example above is meant to demonstrate that you can take data (in the form of NiFi records in a FlowFile) from any source, transform it however you like, and put it into a database table without the table having to exist beforehand. But it can do more than that! If you have an existing table and an extra field in your input data that does not have an associated column in the target table, UpdateDatabaseTable will add the missing column and start populating rows using all the available columns in the input data. Using the above example, let's say we added an extra field named 'newField' with a string value:
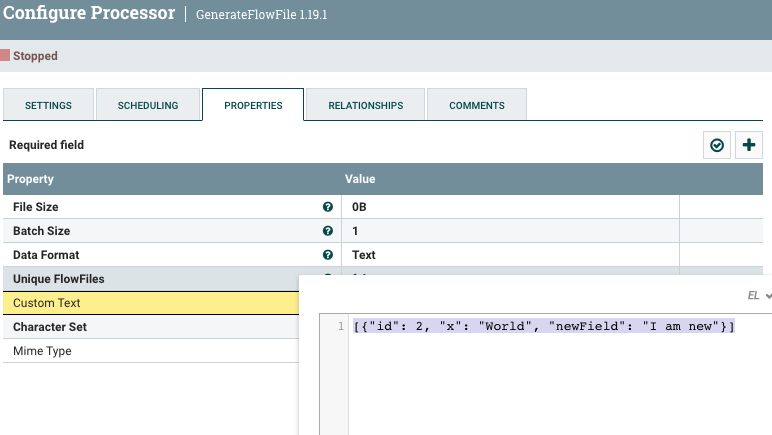
Then we run that FlowFile through UpdateDatabaseTable, and see that the table schema has been updated and the value for that row has been populated, with null as default values for the previously added row:

Hopefully this post has illustrated the potential of the UpdateDatabaseTable processor to make schema migration/drift and database replication techniques much easier in Apache NiFi. As always, I welcome all comments, questions, and suggestions. Cheers!